Introduction
In 2017, the creators of the Allegheny Family Screening Tool (AFST) published a report describing the development process for a predictive tool used to inform responses to calls to Allegheny County, Pennsylvania’s child welfare agency about alleged child neglect. (The tool is not used to make screening decisions for allegations that include abuse or severe neglect, which are required to be investigated by state law [91, p. 5] [76, p. 7].)”
In a footnote on page 14 of that report, the tool creators described their decisions in a key component of the variable selection process — selecting a threshold for feature selection — as “rather arbitrary” and based on “trial and error” [91]. Within this short aside lies an honest assessment of how the creators of predictive tools often view the development process: a process in which they have free rein to make choices they view as purely technical, even if those choices are made arbitrarily. In reality, design decisions made in the development of algorithmic tools are not just technical processes — they also include ethical choices, value judgments, and policy decisions [63]. For example, the “rather arbitrary” threshold used in feature selection could have determined whether a family’s behavioral health diagnoses or history of eligibility for public benefit programs would impact their likelihood of being investigated by the county’s child welfare agency. When developers cast these kinds of design decisions as primarily technical questions [32, 84], they may disguise them as objective, even though they may be made arbitrarily, out of convenience, or based on flawed logic [80].
In this work, recently published at an algorithmic accountability conference, we demonstrate how algorithmic design choices function as policy decisions through an audit of the AFST. We highlight three values embedded in the AFST through an analysis of design decisions made in the model development process and discuss their impacts on families evaluated by the tool. specifically, we explore the following design decisions:
- Risky by association: The AFST’s method of grouping risk scores presents a misleading picture of families evaluated by the tool and treats families as “risky” by association.
- The more data the better: The county’s stated goal to “make decisions based on as much information as possible” comes at the expense of already impacted and marginalized communities — as demonstrated through the use of data from the criminal legal system and behavioral health systems — despite historical and ongoing disparities in the communities targeted by those systems.
- Marked in perpetuity: In using features that families cannot change, the AFST effectively offers families no way to escape their pasts, compounding the impacts of systemic harm and providing no meaningful opportunity for recourse.
Disclaimer: Our results are based on a good faith analysis of the data provided to us by Allegheny County. In an effort to ensure our findings were based on a clear set of assumptions about the county’s model development process, we reached out to the county for comment on our paper on January 23, 2023 and again on February 22, 2023. As of the time of publication of our paper, we have yet to receive comment from the county on our findings. In the event of comment from the county that provides material information that we were not initially provided, adjustments to our analysis may be made.
Related Work
2.1 Algorithmic design as policy
As government agencies increasingly adopt predictive tools in areas ranging from healthcare [13, 30, 94], to education [19, 69], to the criminal legal system [56], and beyond, a growing body of work has focused on understanding the selection and use of algorithmic tools as encoding policy choices, including in the criminal legal system [22], health care policy [33, 81], and environmental regulation [7]. Mulligan and Bamberger [63] argue that, under the current paradigm of government agencies procuring and using algorithmic tools developed by third-party entities, government decision-makers abdicate important policymaking functions, allowing third-party developers’ design decisions to function as policy choices that fail to meet regulatory requirements that agency actions not be “arbitrary and capricious actions.” Keddell [45] explores how predictive analytics tools used in child protection can introduce or exacerbate bias and arbitrariness in decision-making. More broadly, efforts to interrogate technical systems and methods as value-laden artifacts, including in the context of use by government agencies, extends back several decades, spanning philosophy, information science, human-computer interaction, and other fields [24, 25, 54, 62].
Viewing design decisions as policy choices, a related body of work focuses on the actions and functions of data scientists, engineers, researchers, and other actors involved in the design of algorithmic systems, including in shaping the datasets used to build machine learning (ML) systems [8, 60, 61, 70], defining the measurements used to assess ML systems [37, 38, 58], and shaping how system outputs are communicated and explained [9, 11, 51]. Suresh and Guttag [87] outline the lifecycle of ML systems, describing how design decisions by developers throughout the lifecycle can contribute to downstream harms. Levy et al. [50] and Green [31] argue that data science work is inherently political, and Petty et al. [72] highlight that data extraction from communities and the related deployment of statistical tools can be dehumanizing and traumatic. As highlighted by Selbst et al. [84], algorithmic systems never exist in isolated environments; the practice of model development involves making choices that shape the social and political ecosystems in which they are deployed.
2.2 Predictive Analytics in the Family Regulation System
In recent literature, there has been a shift toward referring to the child welfare system as the family regulation system, based on the argument that the system often disproportionately harms poor families and families of color and responds to conditions of poverty with punishment rather than with supportive services [65, 78, 88, 93]. Throughout this paper, we use the terms child welfare and family regulation system interchangeably, and we posit that to understand the use of predictive analytics tools in these contexts, it is important to understand the history and present dynamics of discrimination in the family regulation system [65, 78]. In the United States, Black families experience higher rates of poverty due to historic and ongoing oppression, and Black families have historically experienced elevated family regulation and the highest rates of removal from their families, similar only to Indigenous children in certain states [78]. More than one in two Black children in the United States will be subject to an investigation — and more than one in ten Black children will be forcibly separated from their parents and placed in foster care — by the time they are eighteen [78]. A large body of work has demonstrated the harms of the family regulation system, including how it surveils, criminalizes, and separates families — disproportionately Black and Indigenous families — and treats structural inequality as individual failings [64, 65, 77, 78].
Advocates have long warned against the undue regulation of families by child welfare agencies and, in recent years, have raised concerns about how predictive analytics tools can perpetuate this broad family surveillance [1, 2, 23, 26, 27, 44, 45, 83]. Despite these concerns, child welfare agencies around the United States are increasingly incorporating predictive tools into various stages of their decision-making processes [4]. As of 2021, child welfare agencies in at least 26 states and the District of Columbia had considered using predictive analytics tools, and jurisdictions in at least 11 states were actually using them [82]. These tools can vary in their application context, training data, and outcomes; for a survey and analysis of the different types of predictive analytics tools used in jurisdictions around the country, see Samant et al. [82] and Saxena et al. [83].
2.3 The Allegheny Family Screening Tool (AFST)
Developed by a team of researchers from institutions in New Zealand and the United States—in conjunction with the Allegheny County Department of Human Services (DHS)—the first iteration of the AFST, which we refer to as Version 1 (AFST V1), was launched in 2016 and developed using data from past referrals to and investigations by DHS, medical records, and interactions with the juvenile probation system. The tool operates at the screening stage, when a call screening worker must decide whether to investigate an allegation of child neglect that comes through the hotline [68, 91]. The tool — which is not used to make screening decisions for allegations that include abuse or severe neglect, which must be automatically screened-in for investigation under state law [91, p. 5] ] [76, p. 7] — estimates the probability that a child will be removed from their home by DHS and placed in foster care within two years of being referred to the agency. These probabilities are converted into risk scores between 1 and 20, which are further classified into risk “protocols” using policies developed by the county and the tool’s developers. Since 2016, several additional iterations of the tool have been developed [16, 68, 90].
Significant prior research has focused on evaluating the AFST’s role in the county’s child welfare processes, including examinations of its performance in deployment, its impact on racial disparities in the county’s decision-making processes, and its alignment with the county’s stated goals [23, 26, 86]. Several studies have examined interactions between human decision-makers and the AFST in deployment; De-Arteaga et al. [21] study a technical glitch in the deployment of AFST V1 that led to improperly calculated risk scores, using this data to retrospectively study the behavior of call screening workers interacting with the AFST. Cheng et al. [15] explore the adherence of call screening workers to the AFST’s recommendations and find that, compared to the disparities that would have resulted from strict adherence to the recommendations, call screening workers’ interventions reduce racial disparities in screen-in rates. Several recent works [42, 43] have explored call screening workers’ interpretations of the AFST, including how they incorporate their historical knowledge of the tool and their experience in the field when making screening decisions.
To this landscape, we contribute a novel analysis of the AFST, extending a framework of algorithmic design as policymaking to the AFST’s development and deployment decisions. We surface value judgments embedded in the processes used to build, deploy, and measure the tool, highlighting how these judgments serve as de facto policy decisions without meaningful democratic oversight. Viewed together and promulgated through the algorithm, these choices can exacerbate the harms of structural discrimination for already marginalized communities.
Methods
We analyze de-identified data produced in response to our data request by the Allegheny County Department of Human Services. The data comprised approximately the same number of unique child-referral records from 2010 to 2014 as described in [90, p. 10]. Approximately the same number of records as described in [90, p. 10] had been screened in for investigation. Amongst those screened in, roughly 70% had been designated by the county as training data and roughly 30% were designated as testing data. The data was very similar to the data used to train the version of the AFST described in [90] (we refer to the version described in [90] as AFST V2). The data differed slightly from the AFST V2 training data because of changes in the data that had occurred since the AFST V2 was developed. In particular, the data we analyzed contained a few thousand child-referral records that were not used to train the AFST Version 2, and we were missing a small number of child-referral records that were used in the training process for the AFST Version 2. Both of these data sets contained roughly 800 variables, including, for each family, information about prior referrals and child welfare records, jail and juvenile probation records, behavioral health information, birth record information and demographic information. These variables include indicators for whether a child on a referral is labelled as an “alleged victim” with regard to the referral to the hotline. Throughout our analysis, we use the term “alleged victim” to refer to individuals with this indicator, and we note that in the county’s documentation for the AFST V1, they describe the county’s labelling of which child or children on the referral are indicated as the alleged victim(s) as “somewhat arbitrary” because County staff are required to assess all children on a referral [91, p. 14].
In addition to this data, we were provided with weights and information about several versions of the AFST. This information included the weights for the model corresponding to Version 1 of the AFST (described in [91]) and the weights for Version 2 of the AFST (as described in [90]). We were also given the weights for the model in use at the time we received data (in July 2021), which was developed using the procedures described in [90], but differed slightly from the weights described in [90] because of updates to the model (and therefore the weights) in the time period between when [90] was written and when data was shared with us by the county. In this work, we refer to the iteration of the tool that we analyzed as AFST V2.1 (this is our term, not the county’s, which we use to distinguish from AFST V2 described in [90]). We were also provided with three months of production data from early 2021 for AFST V2.1 and with information about the weights and design process for the version of the tool in use in Allegheny County at the time of writing of this paper (which we refer to as AFST V3). We did not have the training data or production data that corresponded to AFST V1 or V3, and accordingly, we conducted the vast majority of our analysis using the AFST V2.1 weights that were in use at the time data was shared with our team. During the time that the AFST V2 and 2.1 were in use in the county, the “protocols” associated with AFST risk scores changed several times (see [76, p. 7] for further details about the changes over time). In another paper, which has not yet been released, we explore the policy impacts of these changing protocols. For our analyses, we use the protocol most recently in place in the county associated with AFST V2 and V2.1 — and to our knowledge, also currently in place at the time of writing for AFST V3, which applies the:
- “High-risk protocol” to referrals where at least one person in the household has an AFST score of 18 or higher and there is at least one child on the referral under age 16. Referrals in this “protocol” are subject to mandatory screen-in, unless a supervisor overrides that default policy [90, p. 6].
- “Low-risk protocol” to referrals where all AFST scores in the household are 12 or lower and all children on the referral are at least 7 years old [76, p. 7]. For referrals in this protocol, screen-out is recommended.
- “No-protocol” to referrals that do not qualify as either “high-risk” or “low-risk.” This protocol is not associated with explicit screening decisions; discretion is left to call screeners [90, p. 6]. There is no “medium-risk” protocol.
Though the County is using AFST V3 as of the time of writing, to our knowledge, several of the design decisions that we analyze in this work are still shaping this most recent version of the model.
To understand the development and use of the AFST, we conducted an exploratory analysis of the training data used to develop the model, including an examination of the context of data sources, the processes used to construct features, and racial disparities in those features. Our analysis focused, in part, on racial disparities between Black individuals and households and non-Black individuals and households represented in this data, a grouping we used to align with the developers’ reporting of results in [90]. We also conducted a review of documents related to the AFST to understand how policy choices like the screening recommendations associated with each “protocol” were made and promulgated in the context of the AFST. Based on this exploration, we selected three values embedded in the development of the AFST to highlight through the lens of design decisions related to data collection, feature selection, and the post-processing of model outputs. We analyze the impact of these design decisions on screen-in rates, racial disparities, and some of the metrics used in the development process to evaluate the AFST’s performance. Our use of metrics — including Area Under the Curve (AUC), the Cross-Area Under the Curve (xAUC) [40] and False Positive Rates (FPR) — is not intended to suggest how the AFST should have been developed or to analyze whether the tool is “fair.” Reporting results for these purposes would require a complex understanding of the values that are embedded in these metrics. For example, how can we understand the tool’s “accuracy” or evaluate when it makes “errors” when the tool predicts future agency actions, and the ground truth outcome upon which such results are based (whether a child is removed from their home) is informed by the tool, creating a feedback loop? We do not seek to answer such questions here. Rather, where possible, we use many of the same metrics that the county and development team used to justify the tool’s creation and adoption to highlight how these design decisions have a significant effect on the tool’s performance as assessed by its developers, even if we disagree with the values embedded in their assessments of the tool.
Interrogating Values Embedded in the AFST
4.1 Risky by association
In creating the AFST, the developers of the tool made several consequential decisions about how to present risk scores to screening staff, ultimately transforming the model’s outputs — predicted probabilities for individual children — into the format shown to call screeners — a single risk label or numeric score between 1 and 20 representing all children on a referral. In this section, we analyze this series of post-processing decisions [87] related to the aggregation and communication of the AFST’s outputs. We argue first that these decisions are effectively policy choices, and that the AFST’s method of grouping risk scores presents a misleading picture of families evaluated by the tool, treating families as “risky” by association, even when the risk scores of individual family members may be perceived as low. Viewing these decisions as policy choices, we highlight several additional ways these decisions could have been analyzed throughout the AFST’s design and deployment process, which produce varying pictures of how the tool performs.
4.1.1 The AFST’s method of grouping risk scores. In the first public development report about the AFST, the tool’s developers wrote that “of considerable debate and discussion were questions surrounding how to present the risk scores to hotline screening staff” [91, p. 27]. Ultimately, the developers decided to use ventiles to transform the AFST’s predicted probabilities into risk scores between 1 and 20, where each score represents five percent of the child-referral combinations in the testing data used to develop the model [90, p. 10] (in their 2018 analysis of the AFST, Chouldechova et al. characterize the choice of ventiles for the AFST as “not a principled decision” [16, p. 5]). For example, for a referral occurring in 2021, when the AFST V2.1 was in use, a score of 20 for a child indicated that the estimated probability of removal for that child was within the top five percent of probabilities in the testing data used to develop the model, which was based on referrals made between 2010 and 2014. Here, being in the top five percent is a relative measure — as highlighted in other analyses of the AFST [16], individuals who receive the highest possible risk score experience removal less than 50% of the time, a result that might differ starkly from intuitive interpretations of a score in the top five percent.
In addition to using ventiles for the scores, the AFST aggregates risk scores for all children in a household, presenting a single score or label that represents an entire family to call screeners. Though predictions are generated at the child level for each referral, call screeners either see only the maximum score across all children on a referral or a single risk label (e.g., “high risk”) that is determined in part by the maximum score of all children on the referral. Aggregation of risk scores sometimes occurs in other settings, including in the context of pretrial risk assessments in the criminal legal system, where researchers have repeatedly raised concerns about the combination of risk scores related to predictions of different outcomes for the same person [29, 55]. In the context of the AFST, the interpretation of scores for each child is somewhat complex before the household aggregation occurs; this interpretation is further muddied by the aggregation of scores at the referral level. A score of 20 for a referral means that, for at least one child in the household, the estimated probability of removal is within the top five percent of probabilities in the testing data from 2010-2014.
Imagine a referral related to a hypothetical family with three children, aged 5, 10, and 15 respectively, with AFST scores of 5, 10, and 18. One child, the 5-year-old child with a risk score of 5, is labelled as the alleged victim by the county on the referral. How could this information be communicated to the call screener for the referral? As noted in Section 3, the county has a policy of evaluating all of the children on a referral when a call is received — not just those indicated as alleged victims — and this policy pre-dates the AFST [91, p. 14]. But the existence of this policy alone does not answer this question of how scores are communicated to call screeners. For example, one option would be to show each child’s individual score to the call screener, for a total of three scores. Or, with a constraint of only showing one score, the AFST could have displayed the score of the alleged victim (a score of 5), or the maximum score of all children (a score of 18), or a label such as “high-risk” for the entire household based on the score and the children’s ages, akin to the county’s current protocol policy. Under the policy that, to our knowledge, is currently in use in the county, this family would be grouped into the “high-risk protocol.”
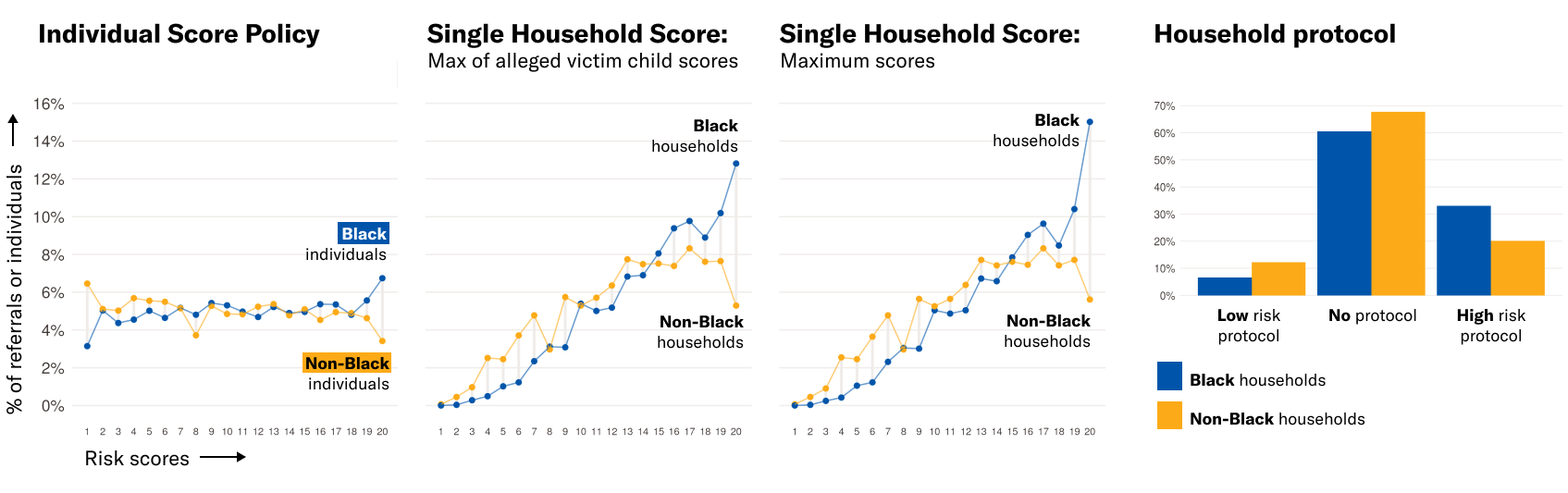
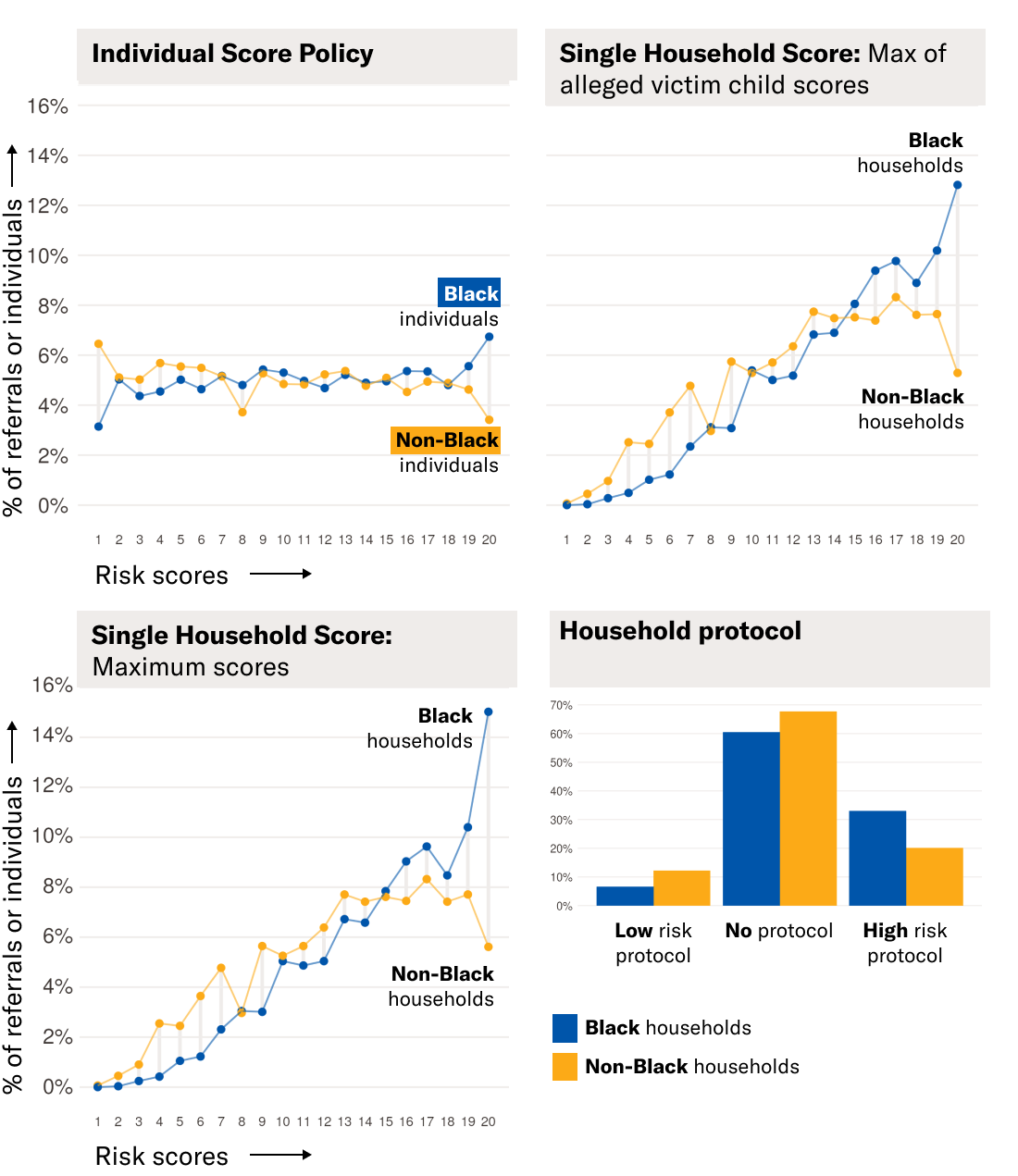
Fig. 1. Distribution of Risk Scores by Race Under Different Scoring Policies. Under policies that assign a single score or protocol to the entire household, risk scores generally increase for all families relative to the individual score policy, and Black households receive the highest risk scores more often than non-Black households. Under the household protocol policy, 33% of Black households are “high risk” while only 20% of non-Black households are “high risk.”
Each of these methods would have significant implications for the distribution of risk scores in the testing data used to develop the model. As highlighted in Figure 1, scoring policies that assign a single score to the entire household confuse the interpretation of the ventile scores. Under the individual score policy (shown in the first panel of Figure 1), each numeric risk score generally corresponds to roughly 5% of the individuals in the data, and similar percentages of Black and non-Black families are assigned each numeric risk score (with the exception of scores 1 and 20). But under the policies that produce one score for each household (shown in the second and third panels of Figure 1), this distribution is heavily shifted upwards and disparately shifted for Black households. (Here, we use the term “Black household” to describe households where at least one person on the referral is recorded as Black in the data given to us by the county; this approach follows the county’s approach for defining Black households to measure racial disparities in screen-in rates.)
For these policies, risk scores generally increase for everyone compared to the individual score policy. But racial disparities in the higher-score ranges are severely exacerbated by the household score policies — non-Black families are more likely to have scores below 10, and Black families are more likely to have scores above 10, with severe disparities at the numeric score of 20. Under a protocol policy like that currently in use in the county — where families are assigned to either the “high-risk protocol,” “low-risk protocol,” or “no-protocol” based on the maximum score in the household and the ages of the children on the referral (shown in the fourth panel of Figure 1) — 33% of Black households would have been labelled “high risk,” compared to 20% of non-Black households. Household size does not account for these disparities; Black households are, on average, assigned higher risk scores than non-Black households of the same size. (Throughout this paper, “household size” refers to the number of children associated with a household-referral in the data given to us by the county. We did not have information about the total household size associated with each referral.) We discuss these results further in a forthcoming extended analysis.
4.1.2 Ways of measuring the AFST’s performance. In the AFST’s development reports, the tool’s developers generally present results about the performance of the AFST using individual scores and measuring individual outcomes, examining whether, for each child, a removal occurred within two years of a referral. These results inform key design decisions, including the modeling approach ultimately selected for the tool [90], but there is a mismatch between how the tool’s results are reported (at the individual level) and how the tool is actually deployed — where each household receives only one score. To evaluate the impact of this mismatch, we define and analyze six different “policies,” representing different ways that risk scores could have been communicated and that outcomes could have been measured in the context of the AFST. These six policies — which could be shared and debated as formal policies about risk scores and household treatment — represent the possible combinations of several different score aggregation methods (using individual scores, maximum household scores, the alleged victim child’s score, or household “protocols”) and outcome measurements (measuring outcomes at the individual level or the household level, examining whether a removal occurred for any of the children on the referral within two years). The specifics of these combinations and a description of how scores and outcomes would be measured under each policy for the hypothetical family discussed in the previous section are included in our forthcoming extended analysis.
For each of these “policies,” we evaluate the AFST’s performance with metrics that were used in the tool’s development reports and analyses about the tool, including the Area Under the Curve (AUC) as in [90] and False Positive Rates (FPR) as defined in [16] for the policies that output ventile scores (the definition of a false positive for the policies that output protocols is included in the extended analysis). We also generate results using the Cross-Area Under the Curve (xAUC) metric proposed by Kallus and Zhou [40], which recognizes that predictive risk scores are often used for ranking individuals in settings with binary outcomes. The developers of the AFST and other researchers, such as Chouldechova et al. [16], make arguments about the fairness of the AFST in part based on race-specific AUC metrics. However, simply grouping by race and computing AUC for each group does not fully reflect the way that models like the AFST are used in practice. The AFST estimates the likelihood of a binary outcome: whether or not a child will be removed within two years. But the scores produced by the AFST are not just utilized in a binary manner: As Chouldechova et al. highlight in their visualization of the referral process [16, p. 12], the AFST informs workers’ screening decisions as well as recommendations about service information and provisions. As such, we can think of the AFST as seeking to rank children who will be removed above those who will not be removed, so we also present results for Black families and non-Black families using the xAUC metric [40].
Our results, summarized in Table 1 and broken down in more detail in our forthcoming extended analysis, indicate that how the tool is measured is consequential for our understanding of how the AFST performs. For each metric, we compute results for the AFST using each “policy,” and demonstrate how these policies produce varying pictures of the AFST’s performance by including the range of possible performance results generated for each metric in Table 1. In our analysis, the AFST often produces the “best” results (e.g., with the lowest FPR and highest AUC) when it is measured as the county measured it: at the individual score and outcome level. But when we measure the AFST in a manner more closely aligned with how it is deployed — using a maximum score policy or a policy of assigning a “protocol” to each family — we sometimes see a lower AUC, a higher false positive rate, and greater racial disparities in performance results (see forthcoming extended analysis for further details). The cross-AUC analysis — across all of the policies — suggests significantly worse performance for Black people compared to non-Black people; associated ROC and xROC curves are included in the forthcoming extended analysis.
Table 1. Performance results for the AFST V2.1 along various metrics, comparing reported results by the tool’s developers for V1 and V2 and our estimations of the range of results each metric could take when using different methods of grouping scores and measuring outcomes at the individual and household level. For more granular results, see the extended analysis.
4.1.3 Discussion. Our findings highlight that post-processing decisions about how to communicate and aggregate model outputs can be incredibly consequential. Determinations about how to measure an algorithmic tool’s performance are not objective; they are subject to multiple alternatives, each with important consequences. These results support the emerging literature examining the importance of measurement in the design and oversight of AI systems, which posits that measurement is in itself a governance process and explores how harms stemming from algorithmic systems can sometimes be traced in part to measurement mismatches [37, 38]. Importantly, in this analysis, we do not impose normative judgments or recommendations about what values would represent an “acceptable” or “good” result on each of these metrics. We also do not intend for this analysis of metrics to be used to argue about whether the tool is “fair,” or to advocate for the use of specific metrics to define “fairness” in this context, recognizing that debates about defining algorithmic fairness in the context of specific decision points fail to address the realities of how algorithmic systems operate in practice. Models that appear to be “fair” using these kinds of metrics can still operate in and exacerbate the harms of oppressive systems [32].
4.2 The more data the better
One of the county’s goals in adopting the AFST, as stated in a 2018 process evaluation, was to “make decisions based on as much information as possible” [36, p. 9]. This “information” included data from the county’s “Data Warehouse” [18] such as records from juvenile and adult criminal legal systems, public welfare agencies, and behavioral health agencies and programs. Each of these databases contributed features that were used in the model, which was developed using LASSO-regularized logistic regression “trained to optimize for the [Area Under the ROC Curve] AUC” [90]. (More precisely, the developers selected the model with the largest value for the regularization parameter among a sequence of candidate values, such that the resulting AUC was within one-standard error of the maximum observed AUC across all candidates [85].)
In this section, we explore the impacts of the inclusion of these features in the model, focusing on features related to behavioral health — which can include disability status — and involvement with the criminal legal system. We highlight concerning disparities related to these features and show that excluding these features from the model would not have significantly impacted the main metric the model was trained to optimize for — the AUC [90]. Ultimately, we find that the county’s stated goal to “make decisions based on as much information as possible” [36] raises concerns and comes at the expense of already impacted and marginalized communities, risking further perpetuation of systemic racism and oppression.
Table 2. AUC generated by retraining the model using the same procedure without juvenile probation (JPO), behavioral health (BH) or "ever in" variables. Removing each of these sets of variables from the training data -- or removing all of them -- reduces the AUC on the test data of the resulting model by less than .01 in all cases.
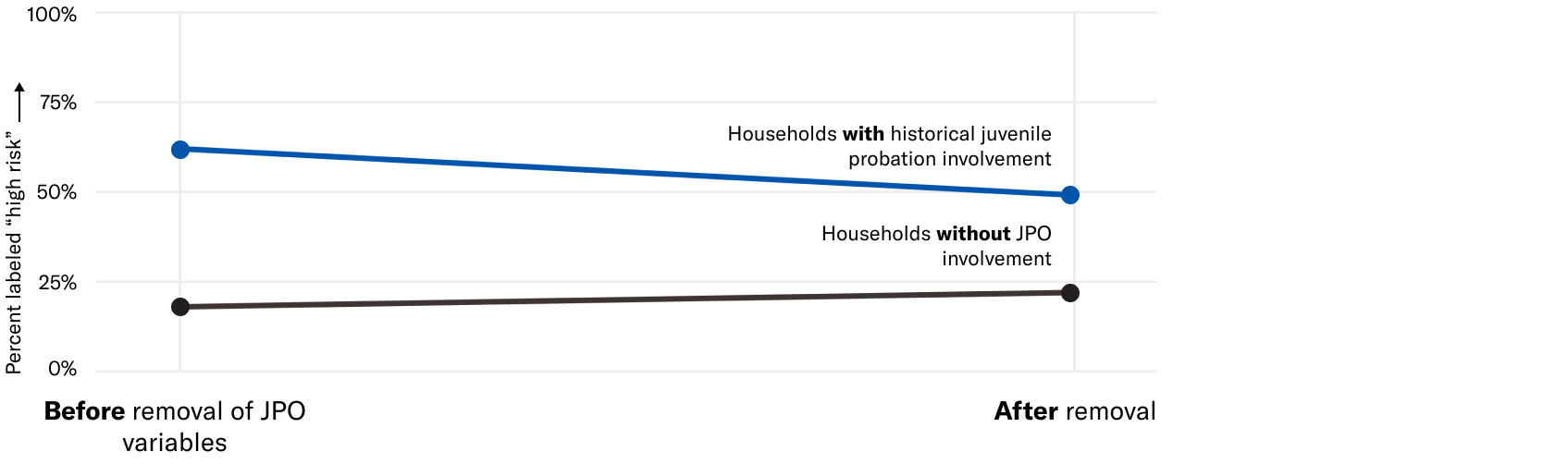
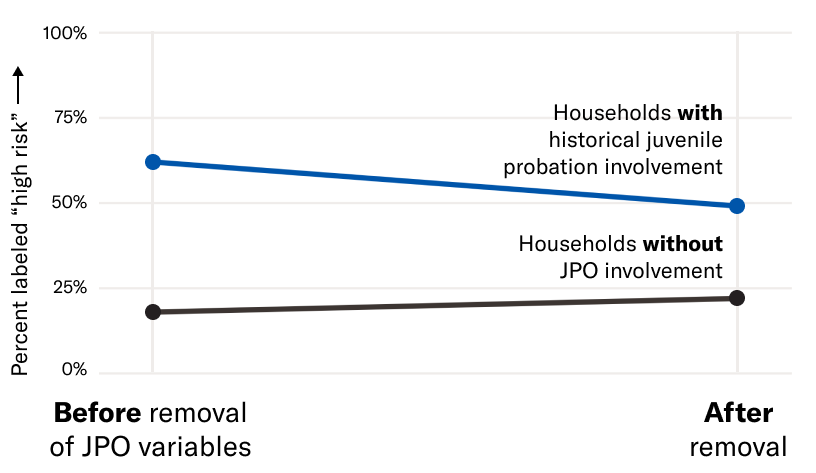
Fig. 2. Households marked by any history with the juvenile probation system are overwhelmingly labeled "High Risk", although less so after removing juvenile probation (JPO) predictors from the training data.
4.2.1 Features from the criminal legal system in the AFST. Every version of the AFST has included features related to involvement with the criminal legal system, including incarceration in the Allegheny County Jail or interactions with juvenile probation (see [91] and [90] for details on these features in V1 and V2 respectively; these types of features are also used in more recent versions of the model). As part of our analysis of the AFST feature selection process — discussed further in our forthcoming extended analysis — we examined whether there were features of the model that were disproportionately associated with Black children compared to white children. Some of the largest racial disparities we found were for features of the model related to juvenile probation, including indicator features for whether the alleged victim had ever been involved with juvenile probation or whether the alleged victim was involved with juvenile probation at the time of the referral (these features are discussed further in [90]). Black alleged victim children were almost three times more likely to have been or currently be on juvenile probation at the time of the referral compared to white alleged victims. The AFST also includes features for whether other members of the household have ever been in the juvenile probation system (see [90]), regardless of how long ago or the details of the case. All of these features can increase an individual’s and household’s AFST score, raising serious concerns that including these racially disparate features — which reflect the racially biased policing and criminal legal systems [53, 75] — could exacerbate and reify existing racial biases. Including these variables has the effect of casting suspicion on the subset of referrals with at least one person marked by the “ever-in juvenile probation” flag, which disproportionately marks referral-households with at least one member whose race as reported in the data is Black. By this definition, 27% of referrals involving Black households in the county data have a member with the juvenile probation flag, compared to 9% of non-Black referral-households. Overall, 69% of referral-households with this flag are Black.
As shown in Table 2, removing the juvenile probation system data from the training data had a minimal impact on the county’s own measure of predictive performance, AUC, which changed from 0.739 to 0.737 (the retraining process is described in more detail in the forthcoming extended analysis). While removing the variables related to the juvenile probation system would have impacted the performance of the model by a negligible amount, it would have reduced the percentage of families affected by juvenile probation labeled as high risk by over 10%, as shown in Figure 2.
4.2.2 Disability-related features in the AFST. In developing the AFST, the county and the research team that developed the tool used multiple data sources that contained direct and indirect references to disability-related information. For example, the first version of the AFST [91] and the version currently deployed in Allegheny County as of the time of writing (AFST V3) include features related to whether people involved with a referral have recorded diagnoses of various behavioral and mental health disorders that have been considered disabilities under the Americans with Disabilities Act (ADA). Versions of the tool have also included features related to public benefits — such as eligibility for Supplemental Security Income (SSI) benefits — that may be related to or potentially proxies for an individual’s disability status [3]. Some iterations of the tool have excluded some of the features pulled from public benefits or behavioral health sources (public reports indicate that the county’s behavioral health agencies focus on services related to “mental health and/or substance abuse” [95]). For example, some public benefits data that was included in AFST V1 was excluded from AFST V2 and V2.1 because of changes in the data format [90, p. 4]. Importantly, these records come from public agencies, so families who access disability-related health care through private services are likely not recorded in these data sources. As highlighted in a 2017 ethical analysis [20] of the AFST commissioned by the county, the people whose records are included in these databases may have no way to opt out of this kind of data collection and surveillance.
We analyze the inclusion of three features directly related to disability status included in V2.1 of the AFST — an indicator variable for whether the “victim child” has any behavioral health history in the database, an indicator variable for whether the alleged “perpetrator” has any behavioral health history in the database, and, for a “parent” with a behavioral health history in the database, the number of days since they were last seen in behavioral health services (see [90, p. 4] for further discussion of these features). These three features are the only variables from the behavioral health data source with a non-zero weight in V2.1 of the AFST. However, disability status may have a larger overall impact on the model if other features in the model, like features related to eligibility for public benefits programs, are proxies for disability status. Because of the weights assigned to these three features in V2.1 and the binning procedure used to convert probabilities to AFST scores, being associated (through a referral) with people who have a disability and access services related to those disabilities — as encoded through these variables — can increase an individual’s AFST score by several points. This finding, discussed further in our forthcoming extended analysis, is not just a theoretical possibility. In both the training data we reviewed and the production data from 2021, we identified several examples of individuals who had identical values for each feature considered by the model except for the indicator variable for whether the alleged “perpetrator” had any behavioral health history in the database. Among these matches, individuals with the behavioral health indicator had scores 0-3 points higher than those without the behavioral health indicator. In addition, retraining the model with this behavioral health data removed as a source of potential feature candidates produces a model with a very similar AUC (see Table 2), raising the concern that the inclusion of these features has an adverse impact without adding to the model’s “predictive accuracy” as defined by the tool developers.
4.2.3 Discussion. Feature selection is one of many consequential decisions with policy impacts in the design of algorithmic tools. There are many different ways to perform feature selection, which is often focused on ensuring that only those variables that allow a model to perform best on a performance metric decided on by the model’s developers are kept in the model [14, 46, 47]. One common approach for feature selection includes using some kind of accuracy maximization as a lone heuristic for feature selection, potentially based on a misplaced belief that there may be a single most-accurate model for a given prediction task [10, 56]. However, emerging research has highlighted the prevalence of model multiplicity — tasks or contexts where several different models produce equivalent levels of accuracy while using different features or architectures [10]. The development of the AFST was guided by AUC-maximization [90], an imperfect measure of accuracy [52], and one that is unable to meaningful distinguish between models with and without disability- and juvenile probation-related features. Given this model multiplicity in the context of the AFST, deciding whether to include or exclude variables from the juvenile probation system is fundamentally a policy choice. Even taking as given a prioritization of some measure of accuracy in the model development process, model multiplicity could allow tool developers and designers to prioritize considerations beyond accuracy [10] — including interpretability, opportunity for recourse, and fairness.
4.3 Marked in perpetuity
When algorithmic decision-making systems are deployed, impacted communities are often left without concrete protections and actionable resources to respond to those systems and harms that may stem from them [49]. Emerging literature focused on the concept of algorithmic recourse [41, 48, 74] explores opportunities for individuals affected by algorithmic systems to contest and challenge system outputs, potentially resulting in changes to the model’s predictions or broader decision-making processes [12, 41, 71, 79]. In the context of the AFST, we examine recourse for call screeners who act on the tool’s outputs and families who are evaluated by the tool, focusing on whether these groups have the ability to be aware of a risk score, understand the specific reasons and model features that led to the risk score determination, and contest both the risk score generated and the inputs to the model. We also explore the use of “ever-in” features — which indicate whether someone involved with a referral has ever been eligible for public benefits programs or been affected by the racially biased criminal legal and policing system — through the lens of algorithmic recourse. We argue that including these static, unchangeable features in the model is a policy choice with serious impacts for families evaluated by the tool, including for opportunities for recourse and contesting the tool’s predictions. We explore racial disparities in the presence of these features and examine whether “ever-in” features add “predictive value” as defined by the tool’s creators. We find that the use of these features compounds the impacts of systemic discrimination and forecloses opportunities for meaningful recourse for families impacted by the tool.
4.3.1 “Ever-in” features and implications for recourse. The AFST includes several features that mark individuals or families in perpetuity — we refer to these collectively as “ever in” predictors, as they are all defined in terms of a person ever having a record in a given data system, and “ever in” is also used by the tool designers to refer to these features [90, 91]. These systems include whether a member of the household has ever been in the Allegheny County Jail or ever been in the Juvenile Probation system, as well as whether household members have ever been eligible for each of a range of public benefits programs administered by Pennsylvania’s Department of Human Services, including Temporary Assistance for Needy Families (TANF) and SSI (see [90, 91] for details on these features). As highlighted in Section 4.2, some public benefits features used in earlier versions of the tool were excluded from this version of the tool. Because they are immutable, these predictors have the effect of casting permanent suspicion and offer no means of recourse for families marked by these indicators. If a parent in the household ever spent time in the Allegheny County Jail (regardless of the charges or whether that charge resulted in a conviction) or was ever eligible for public benefits (meaning they were enrolled in the state’s Medicaid program, whether or not they then used the benefits), they are forever seen as riskier to their children compared to parents who haven’t been ensnared in those systems.
Data stemming from criminal justice and policing systems is notoriously error-ridden and reflects the discriminatory practices and racially disproportionate harms of those systems [53, 75]. Our analysis of referrals from 2010 – 2014 showed that 27% of referrals of households with at least one Black member were affected by the “ever-in” Juvenile Probation predictor, compared to 9% of non-Black referral-households. Similarly, 65% of Black referral-households in the data were impacted by the “ever-in” jail indicator variable, compared to 40% of non-Black referral-households. Examining the public benefits features, we found that 97% of Black referral-households in the data were impacted by at least one of the “ever-in” variables coming from the public benefits data sources, compared to 80% of non-Black referral-households. As is the case with the behavioral health data discussed in the previous section, only families who access or establish eligibility for public services are represented in the public benefits data ingested by the AFST, meaning this data also reflects the historic and ongoing oppression and racial discrimination that contributes to higher rates of poverty for Black families compared to non-Black families and the historical racism that has shaped the benefits programs themselves [73, 78]. Public benefits databases are also not immune to serious data errors. For example, Colorado’s state public benefits database, which is used as a data source for a similar predictive tool used by at least one child welfare agency in Colorado [89], has suffered from systematic errors for decades [35].
The use of these features in the AFST has the effect of creating an additional burden for families who have been impacted by public data systems. This additional burden is imposed not after political debate or an adversarial legal process, but quietly, through the decision to encode membership in a county database with a 1 or 0, and the related decision to use that encoding in a predictive model, despite a lack of demonstrable predictive benefit. When we re-trained the model with the “ever-in” variables excluded from the training data, we found that the baseline model had an AUC of 0.739, and the model without the “ever-in” variables had an AUC of 0.737 (see Table 2). The overall effect of this inclusion is compounded by the decision to aggregate risk scores by taking the maximum score across all individuals on a referral. Figure 3 shows that, as the number of people associated with a referral increases, the likelihood that at least one of them will have some history with the Allegheny County Jail and/or the HealthChoices program increases as well, and this is especially true for referrals associated with households who have at least one Black member. Overall, using the testing data from the model development process and the county’s “high-risk protocol” to measure screen-ins that would have been recommended by the tool, we see referrals where at least one of the associated household members is Black (as recorded in the data) being recommended for screen-in at systematically higher rates than non-Black referral-households, and the disparity grows with the size of the referral (see the forthcoming extended analysis for more detail). For referrals containing five or more individual records, 47.4% of Black referral-households are recommended for screen-in compared to 30% of non-Black referral-households, for a disparity of 17.4%. These disparities persist, but are reduced, after removing the “ever-in” variables before training the model. For instance, the racial disparity for referral-households with five or more people drops to 15.6% under the model without the “ever-in” predictors. We include additional detail and summaries in our extended analysis.
4.3.2 Recourse in deployment. The notion of algorithmic recourse has been defined and operationalized in various ways, invoking different aspects of an algorithmic system’s development and use and focusing on different types of agency that recourse could afford to individuals and groups affected by algorithmic systems [41, 71]. For example, some definitions suggest that algorithmic recourse is just the ability for affected parties to receive explanations about how an algorithm generated a particular output [41], while other definitions suggest that recourse is the ability to not only know how an algorithm reaches its decisions, but also to change decisions stemming from an algorithmic system [92]. Through its use of “ever-in” features, the AFST encodes a lack of recourse for families who have been affected by the criminal legal system or who have utilized public benefits programs.
We can also examine the context in which the tool operates to understand potential algorithmic recourse for people impacted by the AFST, including families and others who interact with the tool. Prior research and reporting about the AFST has touched on many elements of recourse related to the tool’s deployment. For example, reporting about the AFST has highlighted how many affected families may be unaware that a predictive tool is even being used in the child welfare system in Allegheny County [34], and even when families do know a predictive tool is being used, emerging research suggests they are concerned about the tool’s use and oversight but lack a clear avenue for their concerns to be addressed [86].
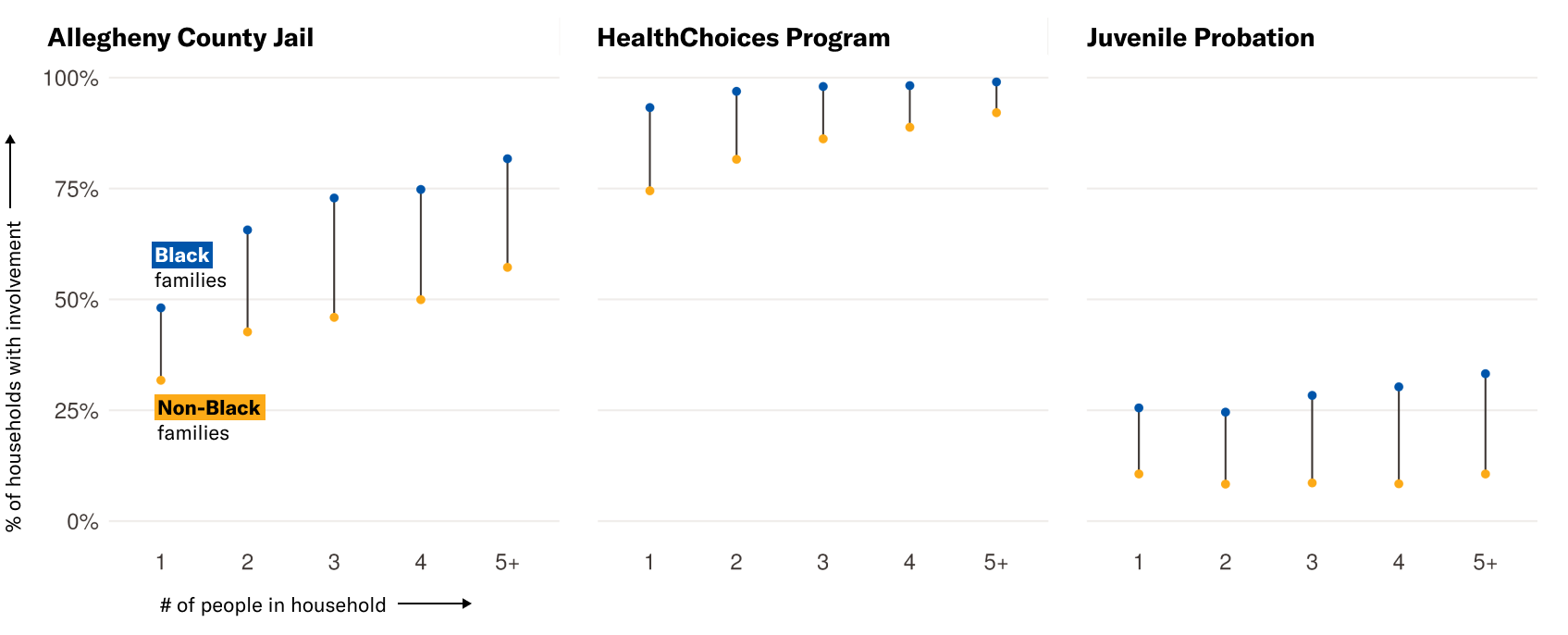
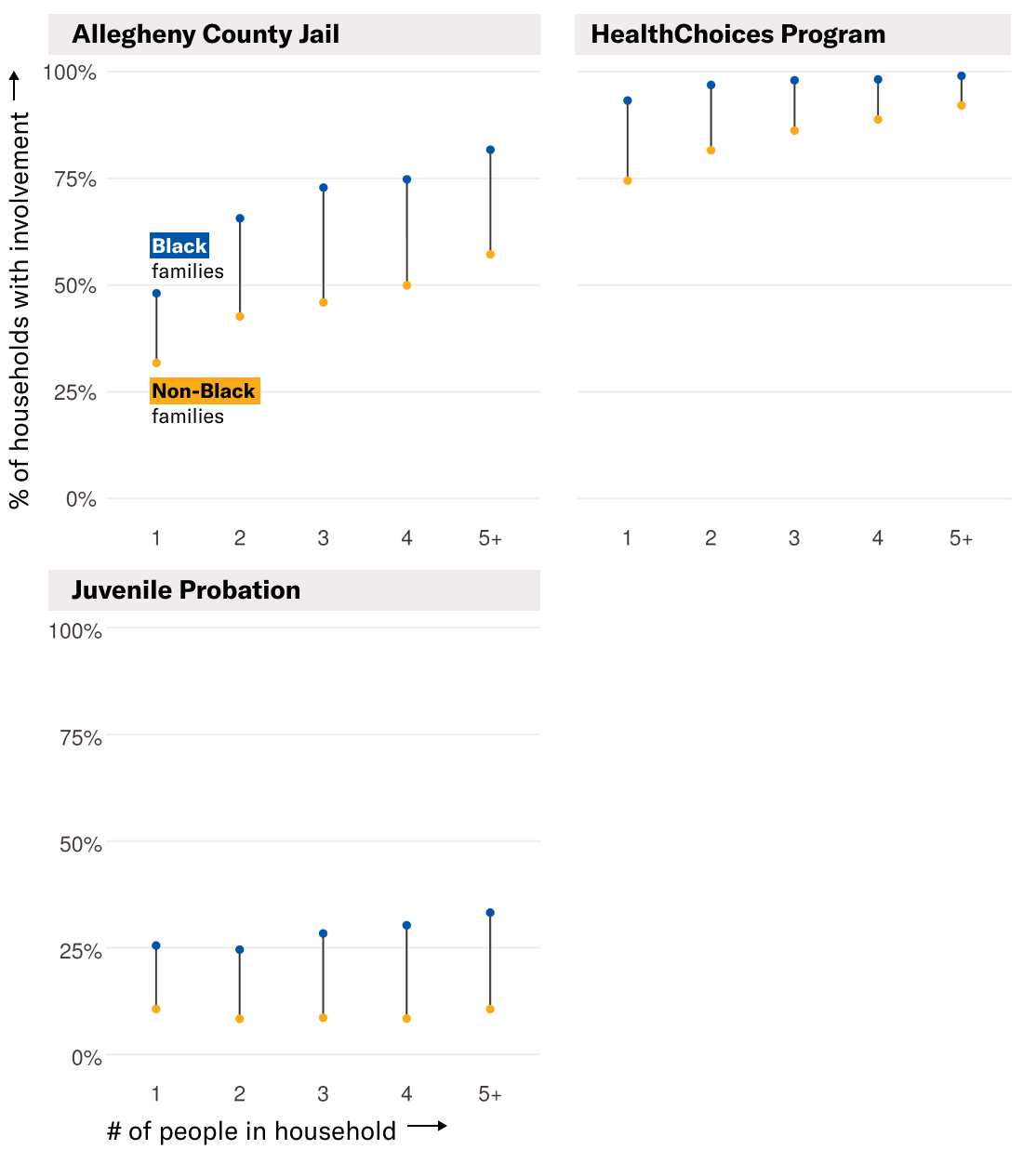
Fig. 3. As household sizes increase, the likelihood that at least one member of the household will have some history with the Allegheny County Jail, the HealthChoices program, or juvenile probation — as marked through “ever-in” features — increases as well. Black households are more likely to have involvement with these systems.
Recourse for call screeners is also an important question; for instance, Cheng et al. [15] found that some call screeners think families with previous system involvement are assigned higher risk scores than other families, and to adjust for this perception, call screeners would sometimes disregard the AFST’s risk assessment determination if they thought that the principal reason for a family’s high risk score was their socioeconomic status. By challenging the outputs of the AFST, child welfare workers reduced the racial disparity in screen-in rates between Black and white children that would have resulted from complete adherence to the algorithm by 11% [15]. Much of this work by call screeners — looking for the reasoning behind racially and socioeconomically disparate risk score outputs from the AFST model — may be guesswork [42], as they are not shown the precise values of features that are used to generate scores.
Conclusion
A 2017 ethical analysis of the AFST described “predictive risk modeling tools” in general as “more accurate than any alternative” and “more transparent than alternatives” [20, p. 4]. In its response to this analysis, the county similarly called the AFST “more accurate” and “inherently more transparent” than current decision-making strategies [67, p. 2]. But when tools like the AFST are created with arbitrary design decisions, give families no opportunity for recourse, perpetuate racial bias, and score people who may have disabilities as inherently “riskier,” this default assumption of the inherent objectivity of algorithmic tools — and the use of the tools altogether — must seriously be called into question. Here, we focused on a limited set of design decisions related to a particular version of the AFST. To our knowledge, several of these design decisions are still shaping the deployed version of the tool, though we were only able to analyze the impacts of these decisions for V2.1 of the tool. We hope future work will expand upon this analysis to improve our understanding of the AFST as well as other algorithmic tools used in these contexts, including structured decision-making tools [5, 6, 28, 39].
In contrast to debates about how to make algorithms that function in contexts marked by pervasive and entrenched discrimination “fair” or “accurate,” Green [32] and Mohamed et al. [59] propose new frameworks that focus instead on connecting our understanding of algorithmic oppression to the broader social and economic contexts in which algorithms operate to evaluate whether algorithms can actually be designed to promote justice [32, 59]. In the years since the initial development of the AFST, impacted community members and others who interact with the AFST have expressed concerns about racial bias and suggested alternatives to the AFST, including non-technical changes to the county’s practices such as improving hiring and training conditions for workers, changes to state laws that affect the family regulation system, and reimagining relationships between community members and the agency [86]. Yet similar tools created by largely the same team of researchers that created the AFST have recently been deployed in Douglas County, Colorado [89] and Los Angeles County, California [66]. The AFST’s developers continue to propose additional use cases for these kinds of predictive tools that rely on biased data sources, even positing that they can be used to reduce racial bias in the family regulation system as part of “racial equity feedback loops” [66]. But as Sasha Costanza-Chock poses in her 2020 book Design Justice [17], “why do we continue to design technologies that reproduce existing systems of power inequality when it is so clear to so many that we urgently need to dismantle those systems?”